
自然场景下的文字检测
这篇blog要讲的是Jaderberg在ECCV2014上发表的Deep Features for Text Spotting,也就是自然场景下的文本识别。
字符识别分为两个步骤:
- 字符定位
- 字符识别
和文档中的字符识别相比,自然场景下的文本识别,由于字符背景的多样和字体本身的多样,导致字符识别在以上两个步骤中都比较困难。这篇文章为我们提供了一个思路,通过深度学习卷积神经网络(CNN)分别做字符的定位和识别。
总结起来,我们从文章中可以抽中如下步骤:
1. 训练一个text/no-text的二分类器以判断输入的图片是否是字符。
输入图片的大小为24×24.整个网络为全卷积网络,即不包含pooling,也没有全连接层。这样做的目的都是为了从一张图片中定位到字符而服务,因为我们需要从一张照片中定位到字符,而不是有现成的算法可以直接定位字符。如果有全连接层,对于非24×24的图片而言,放入CNN会无法forward,因为用24×24训练的全连接层的参数无法用在非24×24的图片上。如果有pooling的话,也会导致最终卷积得到的saliency map和原图不好对准。
这个二分类器也很简单,直接上原图:
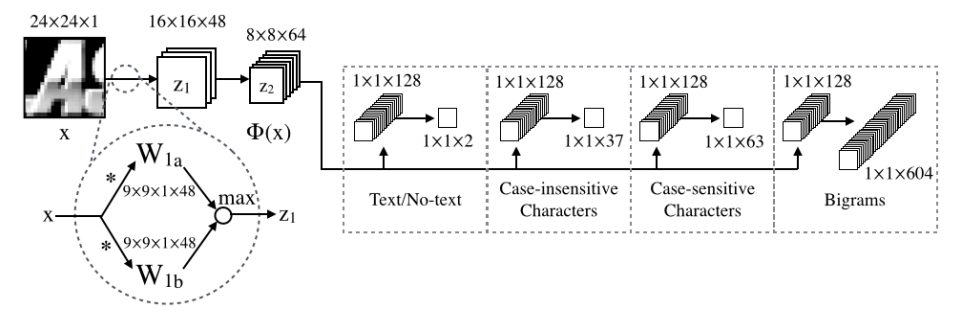
输入24×24的图片,经过48 + 48 = 96个9 × 9的卷积核做一次conv之后,用maxout从96个结果中选出48个,从而得到48个16×16的feature map。接着再来64+64 = 128个9×9的卷积核卷积后得到128个8 × 8的feature map,经过maxout后剩下64个。再然后512个8×8卷积核做卷积。之后的maxout的分组个数为4,所以最终有512/4=128个feature map,且大小为1×1。我们只关注text/no-text分类器。所以只需要输出为2个1×1的feature map即可。
经过这个步骤,我们获得了一个字符/非字符分类器。也就是说你随便放入一张24×24大小的图片,这个分类器都会判定这张图片是字符还是非字符。
2. 对于一个完整的应用,我们需要从一张图片中找到字符的位置。
熟悉sliding window的同学可以能就会想到了,在目标图中建立24×24的sliding window,将窗口中的图片放入步骤1中的分类器,再加上对目标图的scaling,就可以定位字符的位置了。这样确实可以做,不过sliding window太耗时间,对于一张比较大的图,耗时将导致这个程序没有实用性。而我在前文中说到,这个文章的CNN没有全连接和pooling,利用这个特点,我们直接将目标图放到text/no-text分类器中即可。分类器会对这张目标图做卷积,而卷积的过程,实际上是进行了sliding window的过程的。
假设我们的目标图是24×48的:
2.1 如果要做sliding window,则需要从图片的左向右依次取出窗口中的图片,总共取出了25张大小为24×24的图片。这25张图片放入分类器,我们可以判断出25个对应的位置的图片是否是字符。
2.2 如果直接放入分类器,经过计算,最终输出的feature map的大小为2×1×25。2表示的是上文我提到的”所以只需要输出为2个1×1的feature map即可“,而25则恰好表示了25个位置的feature value,如此以来我们就不需要主动的使用sliding window。特别地,一般blas库都对卷积做了很多的优化,计算起来也很快,比主动做sliding window性能好很多。
上文提到的”2”,其实就是2分类器的输出,熟悉CNN的同学知道softmax之后,我们可以得到属于某一个类的概率。所以对于最终的1×25的feature map(其实就是saliency map),我们选出属于字符的位置,并映射到heat map上(比如heat map上每个像素值表示目标图中对应位置是字符的概率,然后设定一个阈值,如大于0.75以上才认为当前位置有字符),就可以确定字符的大概位置。
文章中对heat map又做了些处理。分别对heat map的每一行,计算出两个字符中间的间隙的均值和方差(注意文章中的µ和σ以及3µ−0.5σ),然后在两个点直接连线,从而形成连通域。有了连通域之后,可以画出bounding box(比如先find countour,然后画出每个contour对应的外接矩形,opencv都可以做),利用NMS合并一些bounding box,利用宽高比等再晒去一些可能不是字符的区域。总之最终我们可以良好的扣出目标中的字符位置。注意扣出来的图,只代表一行字符,而不是多行。比如下图:
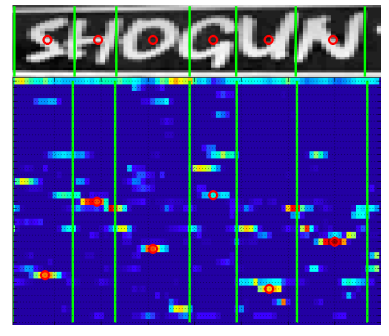
这样我们才好做字符识别。
3. 这时候就可以从上面定位到的代表一行字符的图片中进行字符识别了。
这一步中需要用到字符分类网络,比如不区分大小写的话,有26+10=36个字符,如果我们再加入一个非字符的类别,那么就有了37类,这个分类其文章中也提到了。当我们有了37类的字符分类器后,我们将代表一行文字的图片直接扔到37分类器中,也相当与做了sliding window。对于每一个位置,我们都有一个概率来表示当前位置属于什么字符。这面就和上文提到的类似了。上面的图中,可以看到SHOGUN在对应字符的位置上概率比较大,用红色的圈表示。根据文章所属,蓝色区域从上到下分别表示no-text,0-9,a-z,共37个类别。当然文章中还用了bigram,我没有太关注,感觉不太需要bigram。
经过上述三个步骤我们就可以即定位,又识别字符了。
个人感觉对于字符大小变化多的场景下可能不太好用。因为我们需要对目标图做scaling,然后综合所有scaling的图片,确定字符的位置。如果字符有大有小,一些在某一个scale有可以定位的字符,在其他scale下估计就定位不到了,最终综合的时候,就比较诡异了…